
基本概念
多目标跟踪任务主要用于视频场景,主要是将视频中的物体例如行人、车辆进行编号,并且持续跟踪。
轨迹Track
不同帧里同一个目标的目标框就构成了这个人的轨迹,每个目标的轨迹都有一个独一无二的轨迹编号(trackId).
目标框Det
这个很好理解,视频是由许多图片组成的一个序列,我可以使用目标检测模型对每帧的图片进行推理,即可得到每帧画面的预测狂predDet,与之对应的也有相应的GroundTruth,即gtDet.
匹配Match:
在指标评估阶段,匹配分为两种:目标框的匹配和轨迹的匹配。
目标框的匹配只针对单帧的目标检测而言。对于每一帧的predDet,计算IOU或者其他的度量算法,与gtDet进行一对一的匹配。这些指标与目标检测所用的一致。
轨迹的匹配是针对预测轨迹和真实轨迹的。一条predTrack通过评估算法可能匹配到一条trackId不同的gtTrack.
评价指标
MOTA
$MOTA = 1 - \frac{\sum_t(FN_t + FP_t + IDSW_t)}{\sum_t GT_t}$ GT为一帧上的所有gtBox的数量,FN为假负,FP为假正,IDSW指目标框trackId跳变的情况,一般发生在遮挡、重合时。(IDSW针对TP来说)
这个评价指标比较依赖目标检测的性能,对于IDSW只关注跳变的次数,不关注id的准确性。例如:
truth :1-1-1-1-1-1-1-1-1-1
track1:1-1-2-2-3-3-4-4-5-5
track2:1-1-2-2-1-1-2-2-1-1
其MOTA指标计算结果都是0.6,但2的表现更好,为了解决这个问题,需要IDF1指标。
IDF1
$IDF_1 = \frac{2 \times IDTP}{2 \times IDTP + IDFP + IDFN}$
MOTP
MOTA主要评估检测能力,但没有评估定位能力。
$MOTP = \frac{\sum_{t,i} d_{t,i}}{\sum_t c_t}$, $c_t$表示t帧上的总匹配数量,$d_{t,i}$表示t帧上第i个目标框的定位精度
HOTA
在目标检测评估定位能力时,会使用IOU的指标:
$DetA = IOU = \frac{TP}{TP + FN + FP}$,即交并比,与之类似 HOTA也借用这个思想,来评价两条轨迹的“关联IOU”:
$IOU_{Association} = \frac{TPA}{TPA + FNA + FPA}$
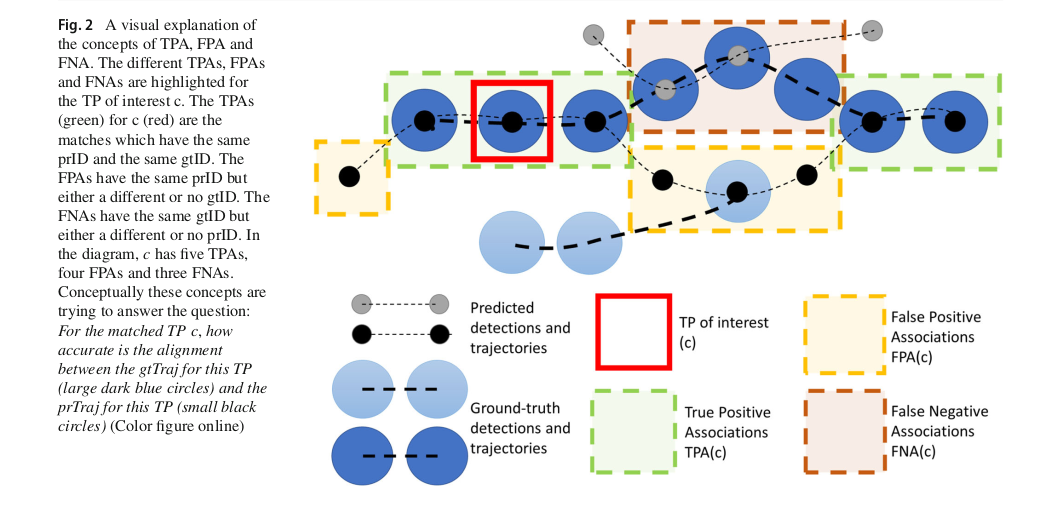 对于一个匹配的TP对,红框,我们使用这个来计算其关联IOU,绿框为匹配的轨迹,黄框和棕框为不匹配的轨迹。
对于一个匹配的TP对,红框,我们使用这个来计算其关联IOU,绿框为匹配的轨迹,黄框和棕框为不匹配的轨迹。
通过计算所有匹配的TP对,可以得到一个整体准确度:
$AssA = \frac{1}{TP} \sum_{c \in TP} IOU_{Association}(c)$
$HOTA_\alpha = \sqrt{DetA_\alpha \cdot AssA_\alpha}$
$\begin{align}HOTA &= \int_{0 < \alpha \leq 1} HOTA_\alpha \ &= \frac{1}{19} \sum_{0.05}^{0.95}HOTA_\alpha\end{align}$
请注意,之前,DetA和AssA都是使用基于某个Loc-IoU阈值($\alpha$)的匈牙利匹配定义的。由于DetA和AssA得分都依赖于Loc-IoU值,我们在不同的α阈值范围内计算这些得分。对于每个阈值,我们计算检测得分和关联得分的几何平均值作为最终得分。然后通过在不同的α阈值上积分,我们将定位准确性纳入最终得分。